

Egal, ob es um Gesundheits-Apps oder um Corona-Tracking-Apps geht, in letzter Zeit schwirren in den Medien häufig Begriffe wie „Anonym“ bzw. „Anonymisierung“ oder „Pseudonym“ bzw. „Pseudonymisierung“ umher. Leider werden diese Begriffe teilweise synonym verwendet. Doch das ist grundlegend falsch! Es macht einen riesigen Unterschied, ob Daten anonymisiert oder ob sie nur pseudonymisiert wurden. Aus diesem Grund habe ich einen älteren Beitrag aus unserem Blog herausgekramt um nochmals auf die Unterschiede eben dieser Begriffe hinzuweisen (ein Hinweis zu unserem alten Beitrag: die Legaldefinitionen finden sich im aktuellen Bundesdatenschutzgesetz so nicht mehr).
Ich möchte mir an dieser Stelle nicht anmaßen ein Urteil zu fällen, ob die Verwendung anonymisierter Daten für diese oder jene Anwendung erforderlich ist, oder ob nicht auch eine Pseudonymisierung ausreichend, bzw. vielleicht sogar erforderlich ist. Ich würde mir nur wünschen, dass alle, die mit den Begriffen jonglieren auch deren Unterschied kennen und in der Diskussion über Anwendungen die korrekten Begriffe verwendet werden.
Mit Hilfe eines einfachen Beispiels lässt sich der Unterschied zwischen Anonymisierung und Pseudonymisierung recht einfach darstellen (vgl. unseren Beitrag hier):
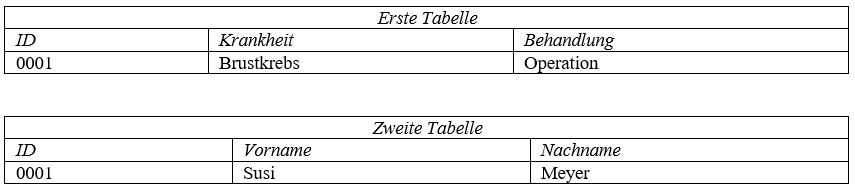
Beispiel: Max hat folgende Tabelle

Anonymisierung: Max möchte seine Tabelle anonymisieren. Max löscht die Spalten „Vorname“ und „Nachname“.

Pseudonymisierung: Max möchte seine Tabelle pseudonymisieren. Max gibt jedem Datensatz in seiner Tabelle eine ID. Dann speichert er in einer zweiten Tabelle die jeweilige ID, den Vornamen und den Nachnamen. Aus der ersten Tabelle löscht er nun die Spalten „Vorname“ und „Nachname“.
Rein rechtlich betrachtet handelt es sich bei pseudonymisierten Daten um personenbezogene Daten, die dem Datenschutzrecht unterliegen. Anonymisierte Daten hingegen sind keine personenbezogenen Daten.
29. Mai 2020 @ 9:17
Das Beispiel ist ganz gut gewählt. Aber teilweise sieht es in der Praxis anders aus. Nehmen wir an ich habe eine Tabelle wie oben beschrieben und lösche nun die Spalten Vorname, Nachname. Dieser Löschvorgang wird in einer Protokoll-Datei hinterlegt, in etwas in folgender Form:
1.2.20 9:23 Löschung Vorname, Nachname von ID 001 durch XXX
Diese Protokoll-Datei ist nicht von jedem einsehbar, sondern „nur“ vom IT-Administrator. Somit also nur mit erhöhtem Aufwand einsehbar.
Ist es nun immer noch eine Pseudonymisierung oder ist es, wegen dem Aufwand, eine Anonymisierung?
29. Mai 2020 @ 12:22
Hallo Thorsten,
das kommt darauf an, was tatsächlich in Log steht. Wenn im Log der echte Vorname und der Nachname, die da gelöscht wurden, also der Wert des Datenfelds, stehen, dann würde ich das auch als Pseudonymisierung sehen, zumindest solange, bis auch das Log gelöscht wurde.
Wenn im Log steht, dass Vorname und Nachname gelöscht wurden, ohne dass die alten Werte drinstehen, dann ist das echt anonymisiert.
Auch beim Vorliegen von Backups kann nur von einer Pseudonymisierung gesprochen werden.
Rein technisch ist eine Anonymisierung erst dann eine Anonymisierung, wenn es technisch unmöglich ist, den Personenbezug wiederherzustellen. Solange der Personenbezug wiederherstellbar ist, völlig egal, wie hoch der Aufwand ist, ist es eine Pseudonymisierung.
Soweit zur rein technischen Ansicht. Allerdings ist es je nach Schutzbedarf sicherlich in einigen Fällen ausreichend, wenn z.B. die Logdatei nur von einem sehr eingeschränkten Personenkreis einsehbar ist. Hier betreten wir dann das Feld der Schutzbedarfe, die für verschiedene Anwendungen festzulegen sind. Du siehst, hier können wir dann wieder ganz viel diskutieren. Mir ging es in dem Artikel nur darum, den Unterschied der Begriffe darzulegen.
Viele Grüße
Daniela Windelband